VOXECURE — AI 성문(Voiceprint) 분석 플랫폼
음성에서 화자의 고유한 특성을 추출하여 비교 분석하는 AI 기반 성문 분석 소프트웨어입니다. 보이스피싱, 협박, 허위 신고 등 범죄 사건 수사에 활용할 수 있는 법과학(Forensic) 수준의 화자 식별 시스템을 웹 기반으로 구현했습니다.
핵심 음성 분석 엔진은 서울대학교 Human Interface Laboratory(휴먼인터페이스연구실)에서 연구 개발한 딥러닝 모델을 제공받아 탑재하였으며, (주)민트기술이 이를 실무에 적용 가능한 프로덕션 수준의 웹 애플리케이션으로 설계, 개발, 배포하였습니다. GS 인증(소프트웨어 품질 인증)을 획득한 제품입니다.
프로젝트 개요
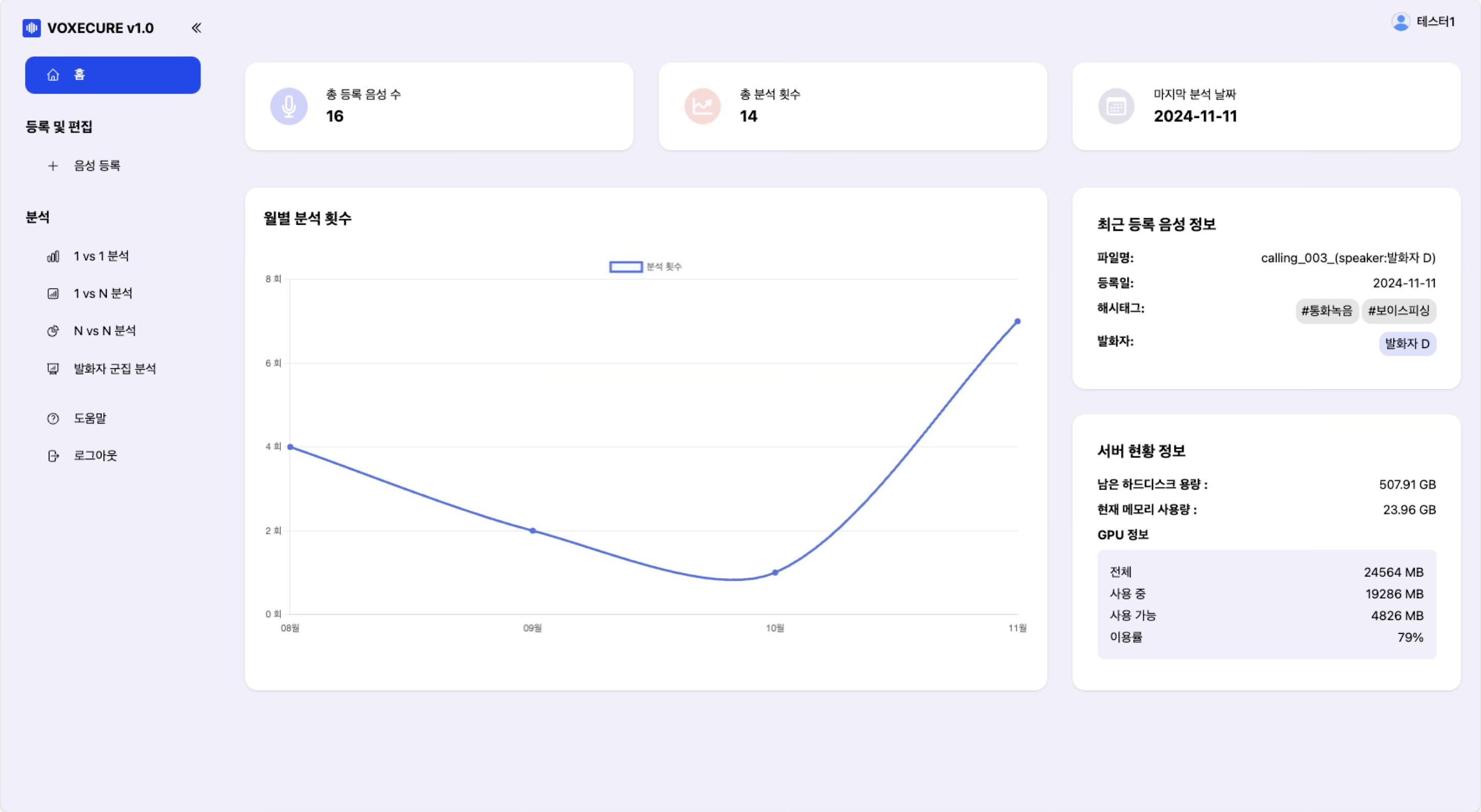
VOXECURE는 녹음된 음성 파일에서 화자를 자동으로 분리(Diarization)하고, 각 화자의 음성 특징 벡터(Speaker Embedding)를 추출한 뒤, 화자 간 유사도 분석과 우도비(Likelihood Ratio) 계산을 수행하는 시스템입니다.
기존의 외국 성문 분석 소프트웨어는 한국어 음성에 대한 분석 정확도가 낮고, 사용이 복잡한 한계가 있었습니다. VOXECURE는 한국어 음성에 최적화된 분석 모델과 직관적인 웹 UI를 결합하여, 수사기관과 전문가가 쉽고 정확하게 성문 분석을 수행할 수 있도록 설계되었습니다.
시스템 구조
VOXECURE는 3개의 독립적인 서비스로 구성된 마이크로서비스 아키텍처를 채택하고 있으며, Docker Compose로 통합 배포됩니다.
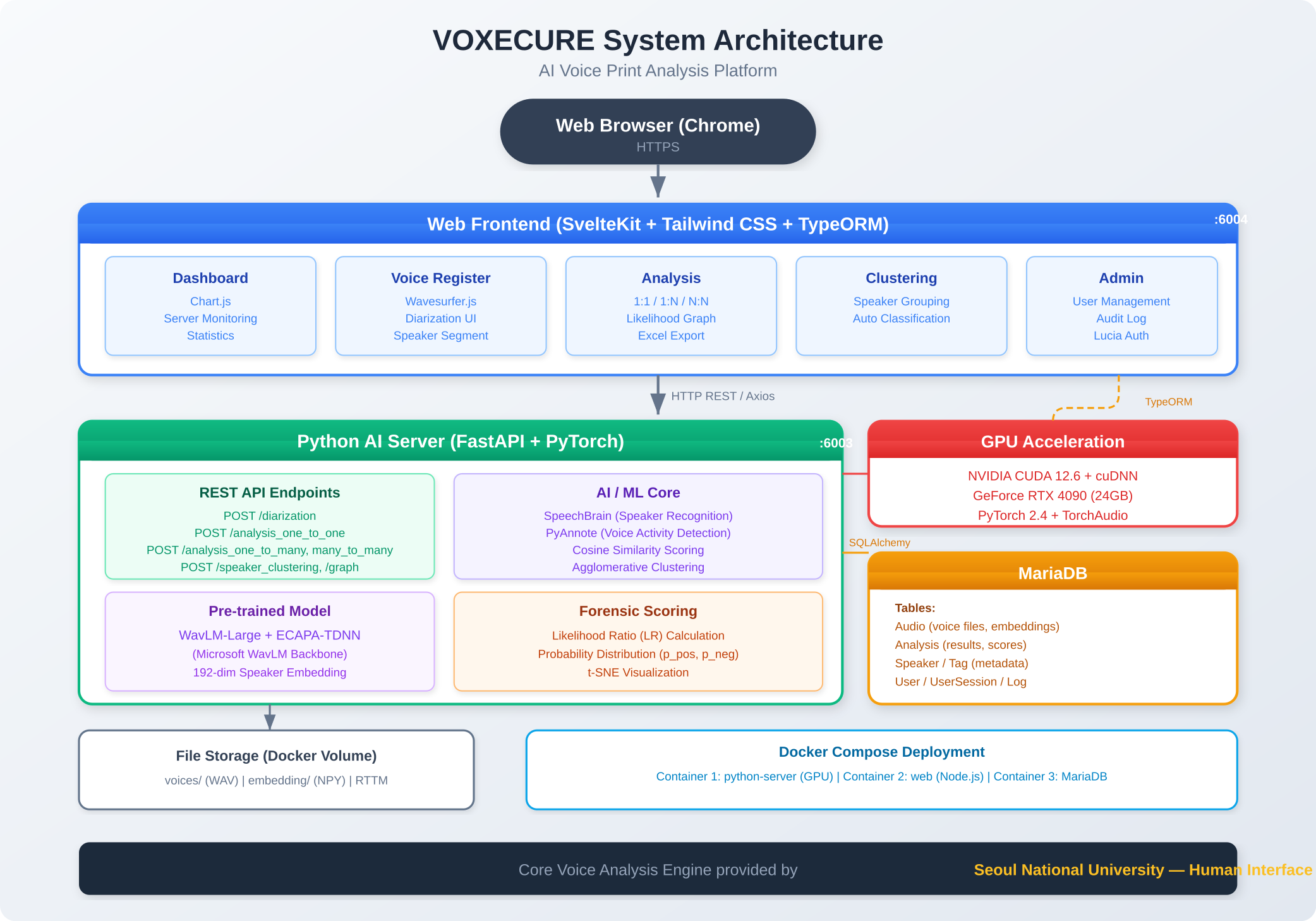
| 구성 요소 | 기술 스택 | 역할 |
|---|---|---|
| Web Frontend | SvelteKit, Tailwind CSS, DaisyUI, TypeORM, Chart.js, Wavesurfer.js | 사용자 인터페이스, 데이터 시각화, 음성 파형 편집 |
| Python AI Server | FastAPI, PyTorch 2.4, SpeechBrain, PyAnnote.audio, scikit-learn | 음성 분석 엔진, 화자 분리, 임베딩 추출, 유사도 계산 |
| Database | MariaDB, SQLAlchemy ORM | 음성 메타데이터, 분석 결과, 사용자/세션/로그 관리 |
| GPU Server | NVIDIA CUDA 12.6 + cuDNN, RTX 4090 (24GB VRAM) | 딥러닝 모델 추론 가속 |
핵심 AI 엔진 — 서울대학교 연구실 제공
VOXECURE의 핵심 음성 분석 엔진은 서울대학교 Human Interface Laboratory(휴먼인터페이스연구실)에서 연구 개발한 딥러닝 모델에 기반합니다. (주)민트기술은 이 연구 성과를 제공받아 실제 수사 현장에서 사용 가능한 프로덕션 소프트웨어로 구현하였습니다.
WavLM-Large + ECAPA-TDNN 모델
화자 식별의 핵심은 음성에서 화자 고유의 특징 벡터(Speaker Embedding)를 추출하는 것입니다. VOXECURE는 Microsoft의 WavLM-Large를 백본(Backbone)으로, ECAPA-TDNN을 헤드(Head)로 결합한 사전학습(Pre-trained) 모델을 사용합니다.
- WavLM-Large: 24층 Transformer 기반 음성 기반 모델(Speech Foundation Model). 16kHz 오디오에서 고수준 음성 표현을 학습
- ECAPA-TDNN: Time-Delay Neural Network 기반 화자 인식 모델. Squeeze-and-Excitation 블록, ResNet 잔차 연결을 통해 채널 어텐션 적용
- 192차원 임베딩 벡터 출력: 고정 크기의 화자 특징 벡터로, 빠른 유사도 계산 가능
- Cosine Similarity 기반 유사도 측정 + 우도비(Likelihood Ratio) 계산으로 법과학 수준의 정량적 분석 제공
Voice Activity Detection (VAD) + Speaker Diarization
PyAnnote.audio 기반의 음성 활동 감지(VAD)와 화자 분리(Diarization)를 수행합니다. 녹음 파일을 업로드하면 자동으로 발화 구간을 감지하고, 화자별로 구간을 분리하여 색상으로 구분된 파형(Waveform)으로 시각화합니다. 사용자는 마우스 드래그로 발화 구간을 미세 조정할 수 있습니다.
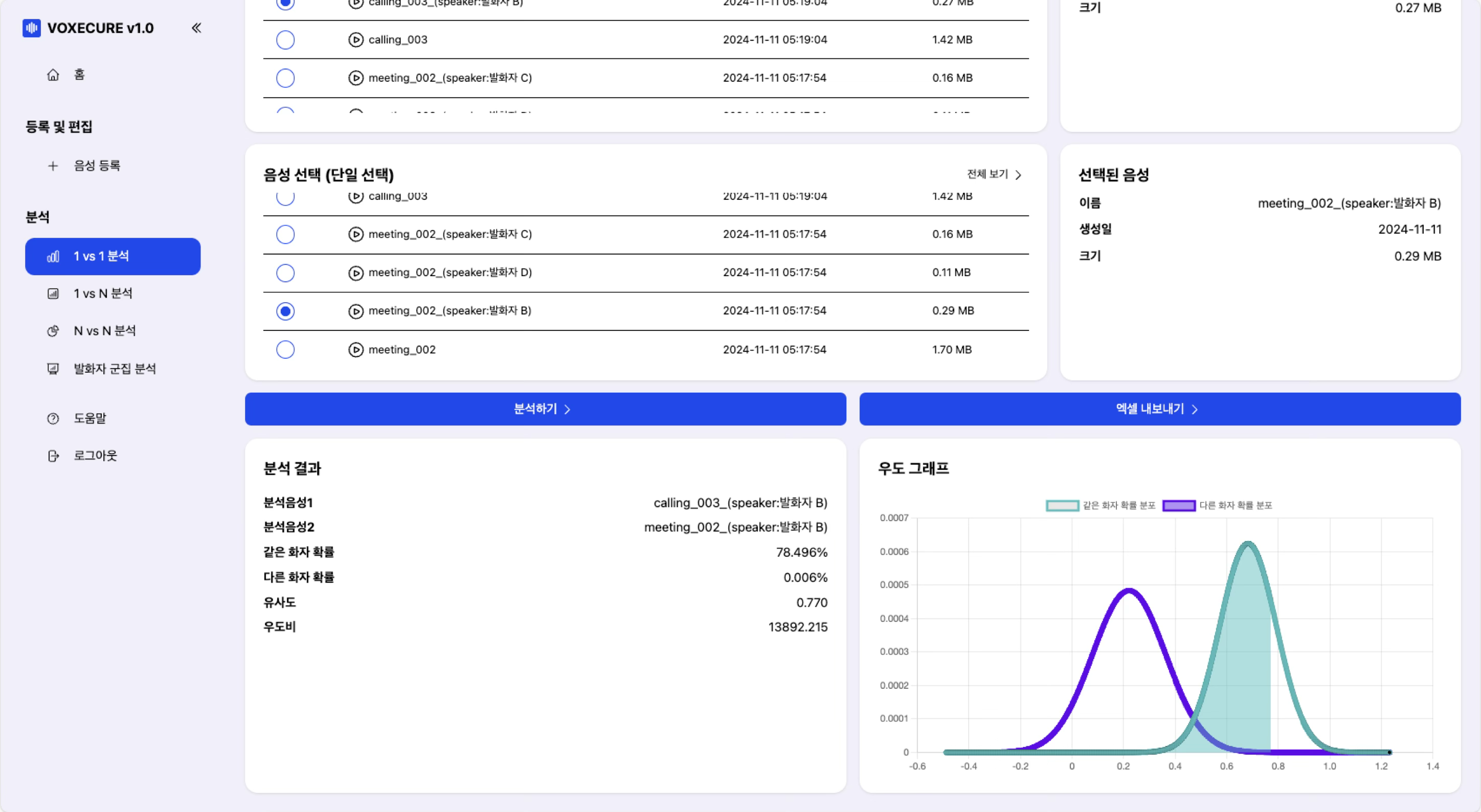
법과학(Forensic) 분석 지표
- 같은 화자 확률(Same Speaker Probability): 두 음성이 동일 화자로부터 나온 확률
- 다른 화자 확률(Different Speaker Probability): 두 음성이 서로 다른 화자에게서 나온 확률
- 유사도(Similarity): 코사인 유사도 기반 수치 (-1~1, 높을수록 유사)
- 우도비(Likelihood Ratio): 같은 화자 확률 / 다른 화자 확률. 법정 증거 평가에 사용되는 베이지안 지표
- 확률 분포 그래프: 같은 화자 분포와 다른 화자 분포의 중첩 시각화
주요 기능
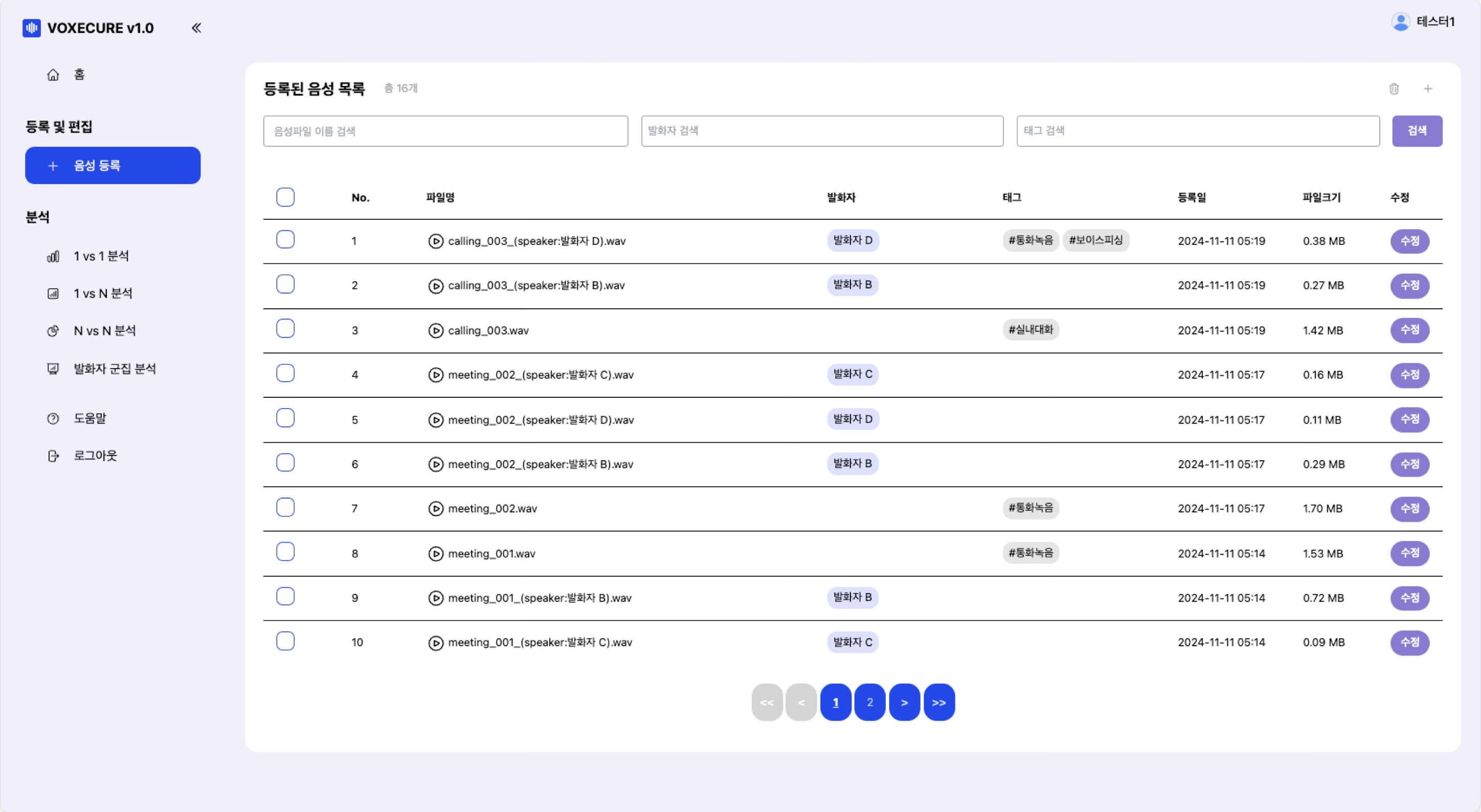
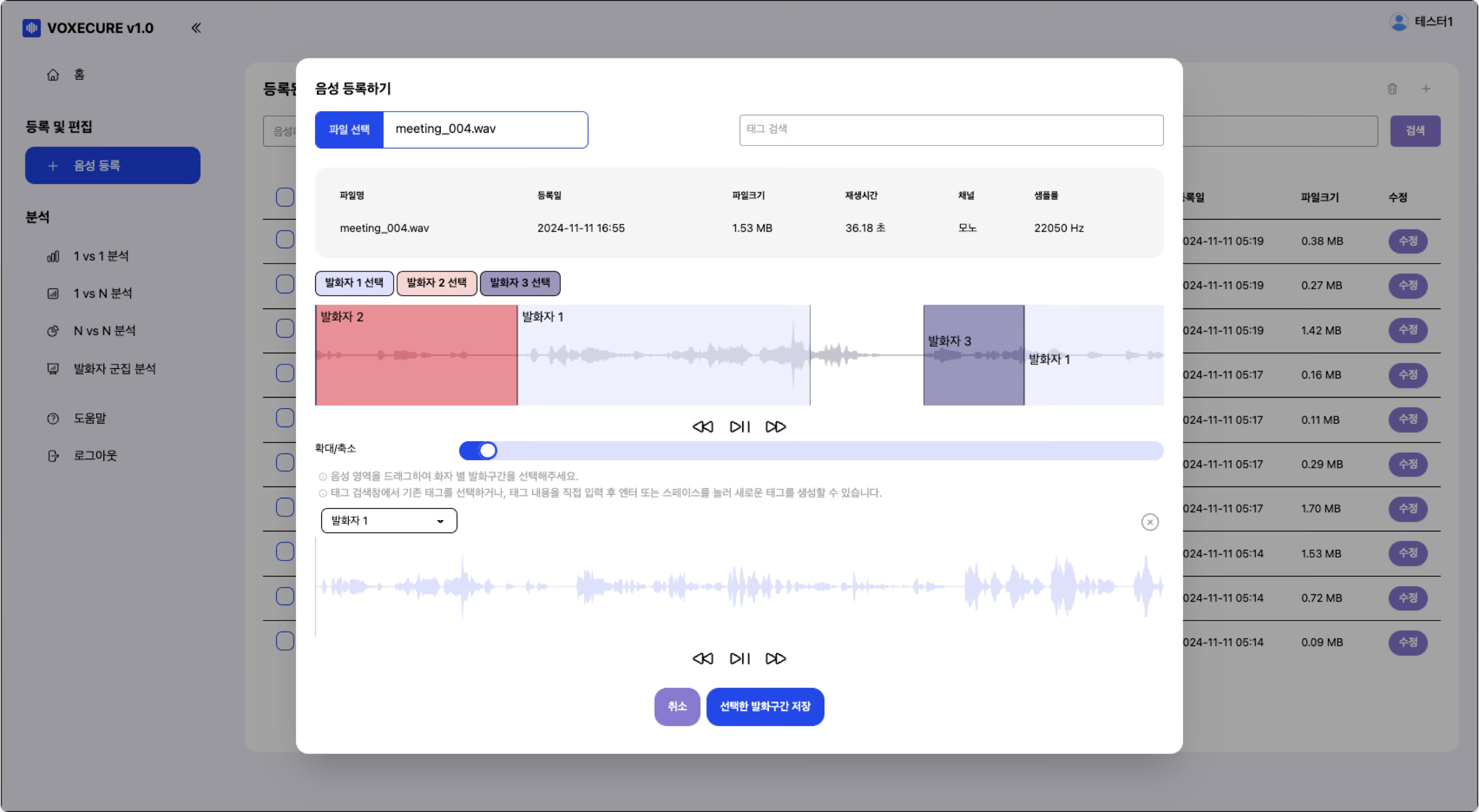
1. 음성 등록 및 화자 분리 (Diarization)
WAV 파일을 업로드하면 시스템이 자동으로 음성 활동 감지(VAD)와 화자 분리(Diarization)를 수행합니다. 분석 결과는 Wavesurfer.js 기반의 인터랙티브 파형 에디터로 표시되며, 각 화자의 발화 구간이 색상으로 구분됩니다. 사용자는 발화 구간을 드래그하여 조정하거나, 발화자를 선택/변경하고, 해시태그를 부여하여 음성을 체계적으로 관리할 수 있습니다.
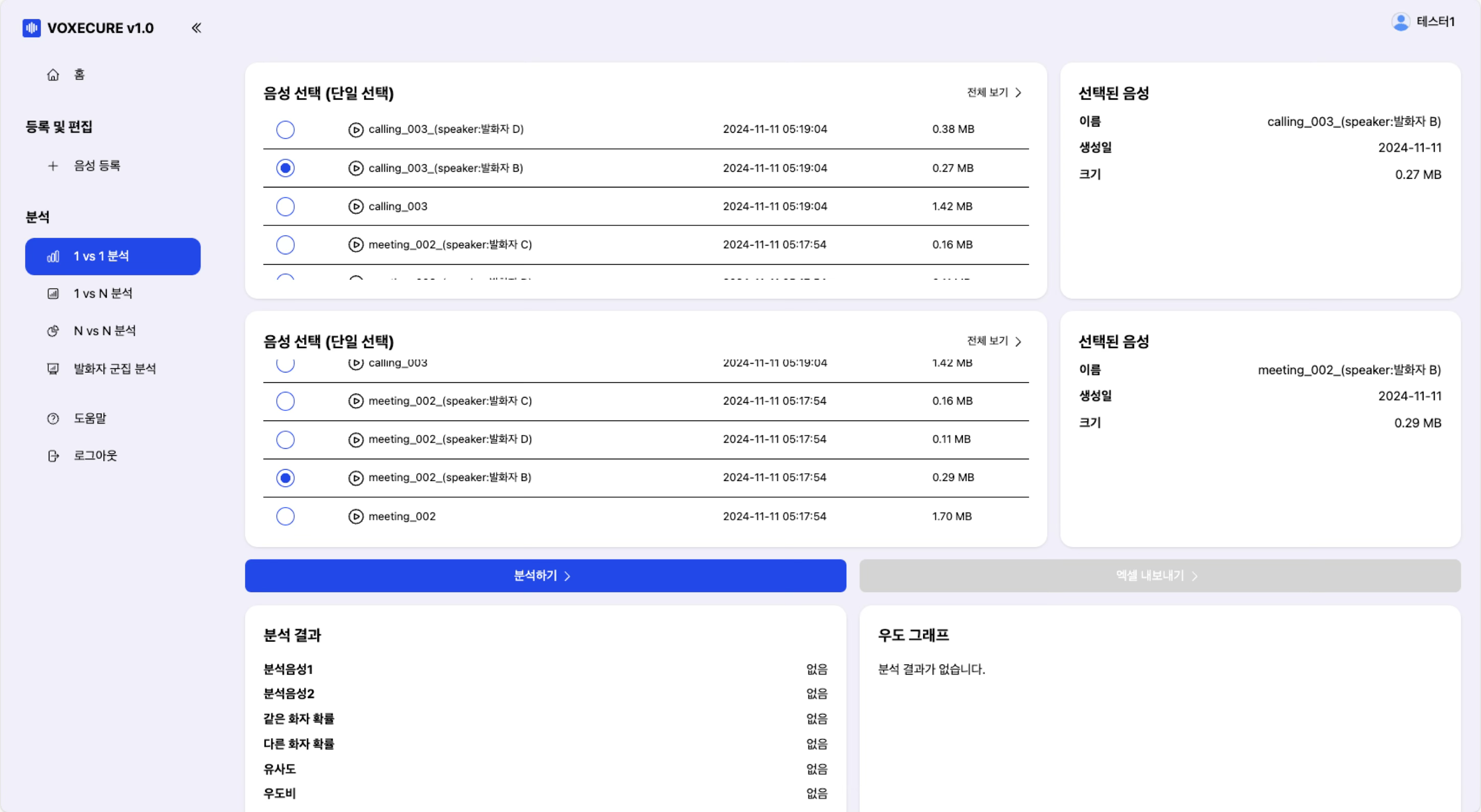
2. 1 vs 1 분석 — 두 음성 간 화자 비교
두 개의 음성 파일을 선택하여 동일 화자 여부를 분석합니다. 분석 결과로 같은 화자 확률, 다른 화자 확률, 유사도, 우도비를 제공하며, 우도 그래프(Likelihood Distribution Graph)를 통해 같은 화자 분포와 다른 화자 분포의 교차점을 시각적으로 확인할 수 있습니다. 분석 결과는 Excel 파일로 내보내기가 가능합니다.
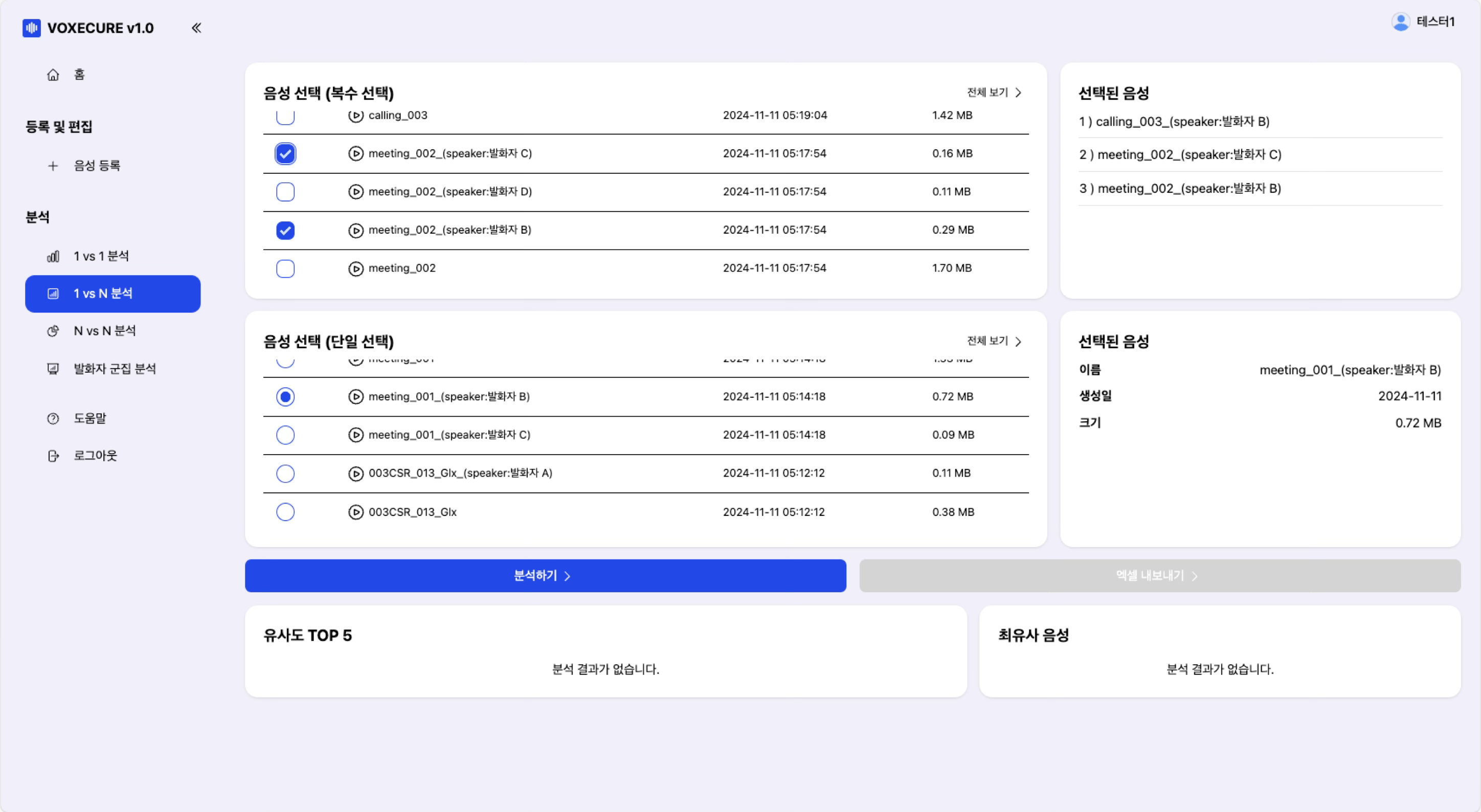
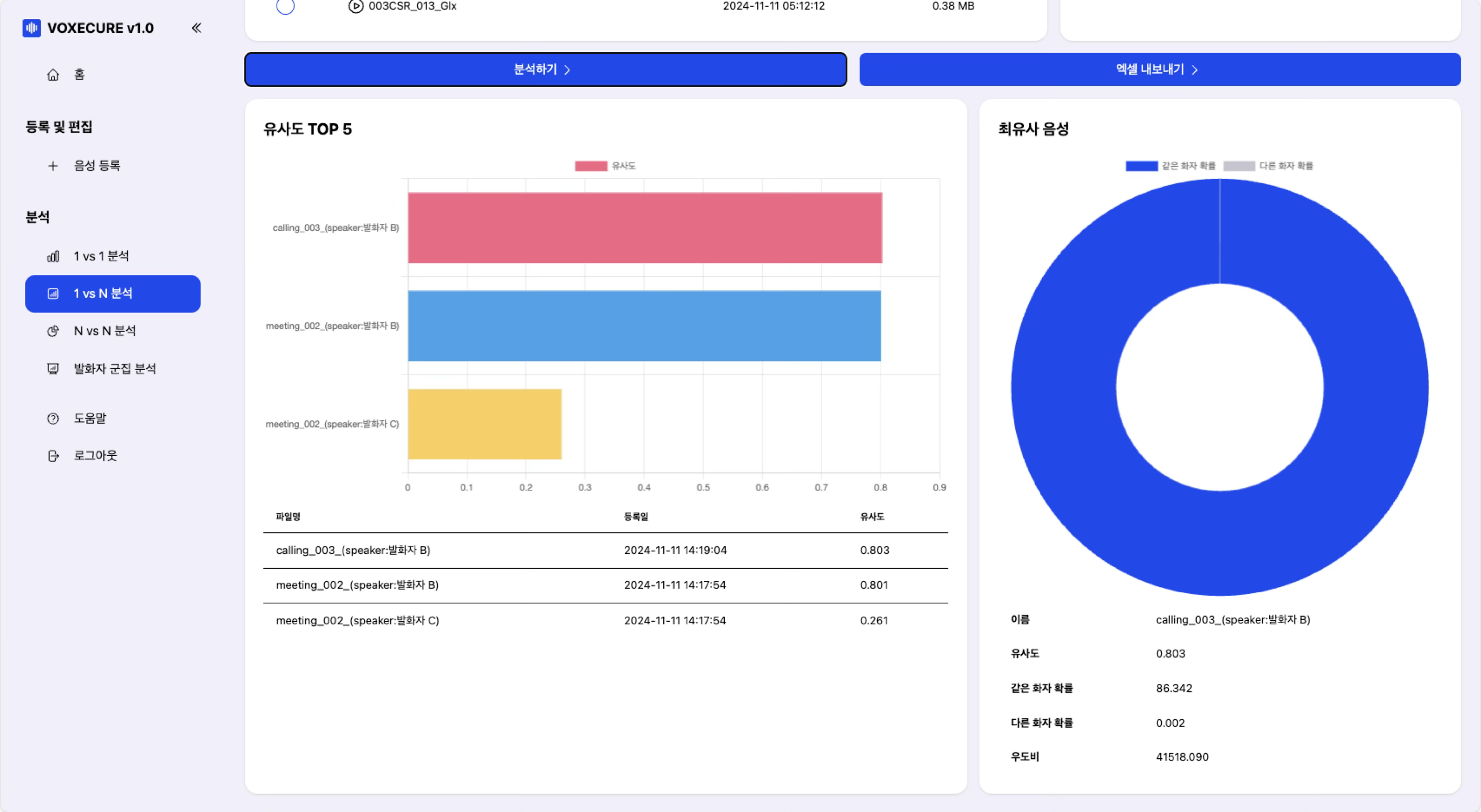
3. 1 vs N 분석 — 다수 음성에서 특정 화자 검색
하나의 기준 음성을 여러 음성과 비교하여 가장 유사한 화자를 랭킹합니다. 유사도 TOP 5를 수평 바 차트로 시각화하고, 가장 유사한 음성의 상세 정보와 도넛 차트(같은/다른 화자 확률 비율)를 제공합니다. 용의자 음성과 다수의 통화 녹음을 비교하여 동일 화자를 빠르게 식별하는 데 활용됩니다.
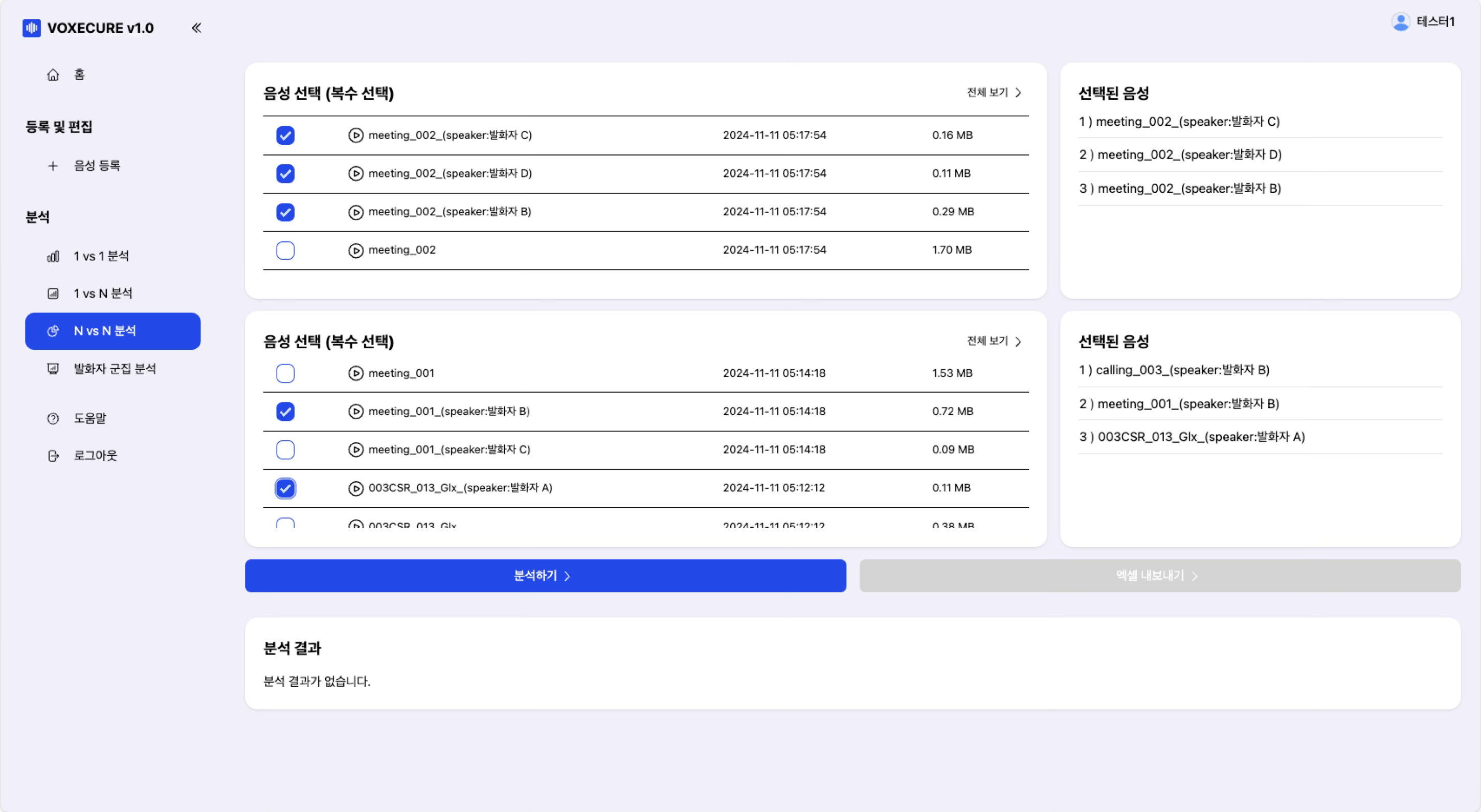
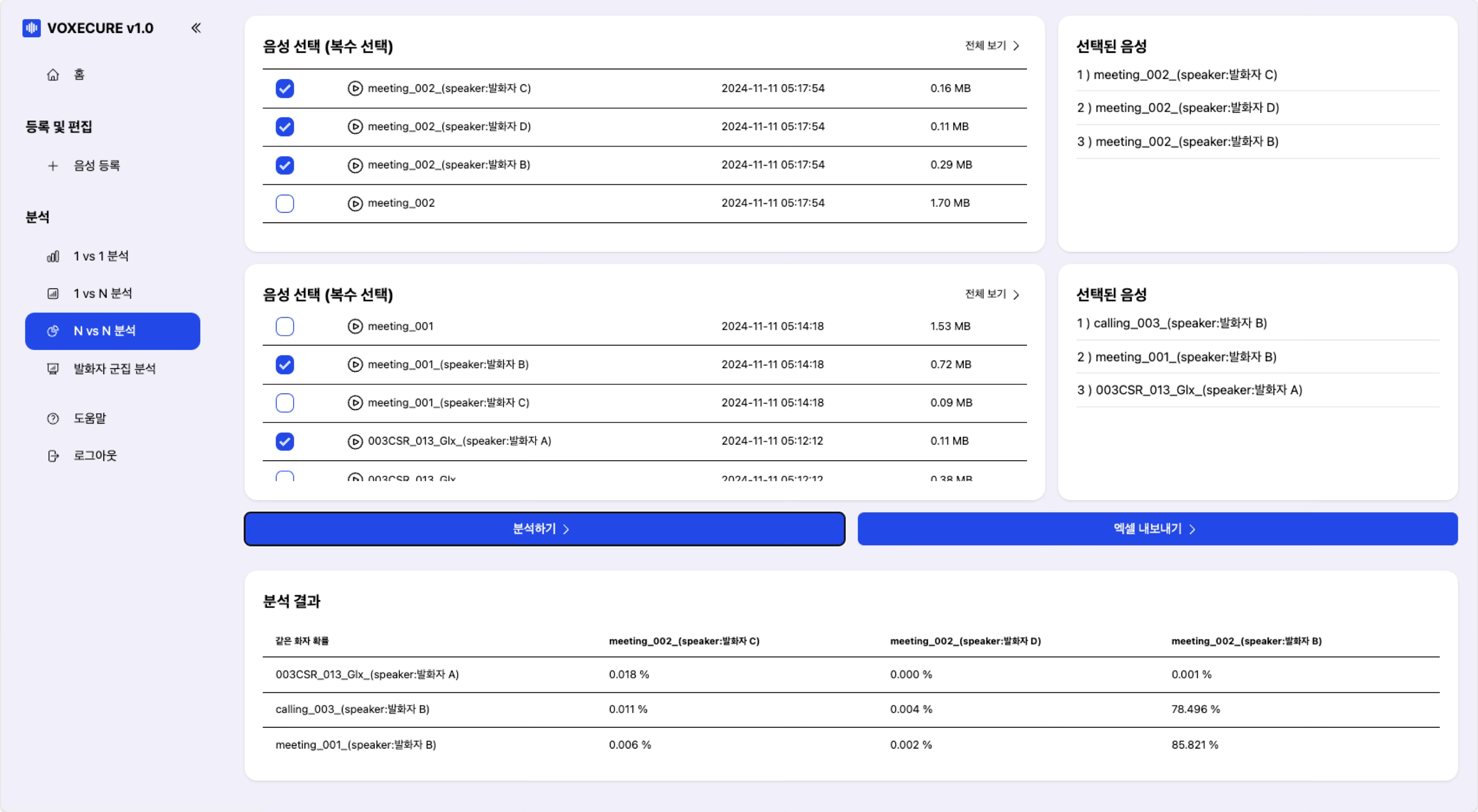
4. N vs N 분석 — 다대다 교차 비교
두 그룹의 음성을 선택하여 모든 쌍(Pairwise)에 대한 같은 화자 확률을 교차 비교 매트릭스(Matrix)로 출력합니다. 다수의 통화 녹음에서 동일 화자가 여러 건에 걸쳐 관여했는지를 한 번에 파악할 수 있습니다. 결과는 유사도, 같은 화자 확률, 다른 화자 확률, 우도비를 포함한 상세 Excel 파일로 내보낼 수 있습니다.
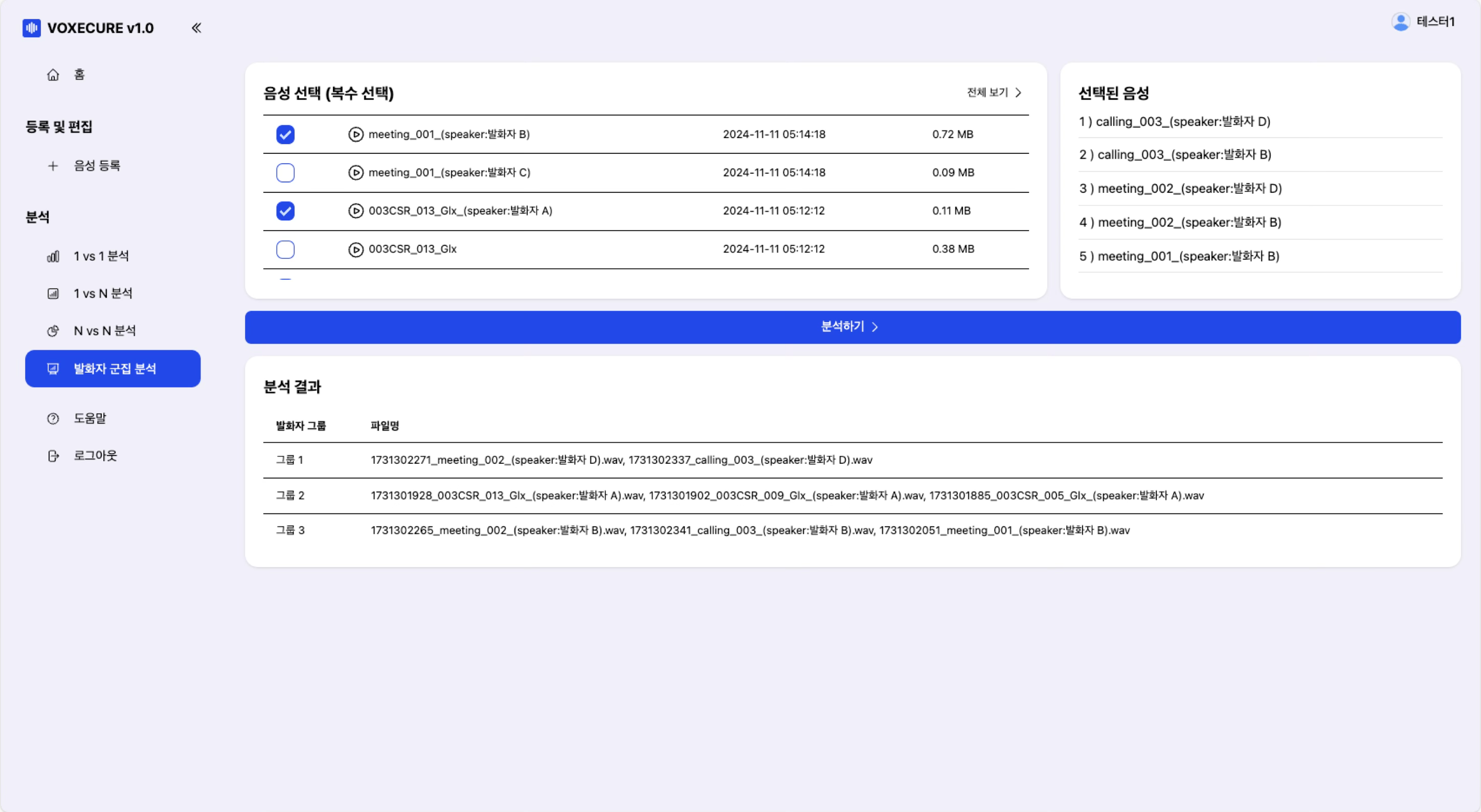
5. 발화자 군집 분석 (Speaker Clustering)
여러 음성 파일을 선택하면 Agglomerative Clustering(계층적 군집화) 알고리즘을 사용하여 유사한 화자끼리 자동으로 그룹화합니다. 화자 수를 사전에 지정할 필요 없이, 유사도 임계값(threshold=0.4) 기반으로 자동 분류합니다. 다수의 익명 통화 녹음에서 몇 명의 서로 다른 화자가 관여했는지를 파악하는 데 유용합니다.
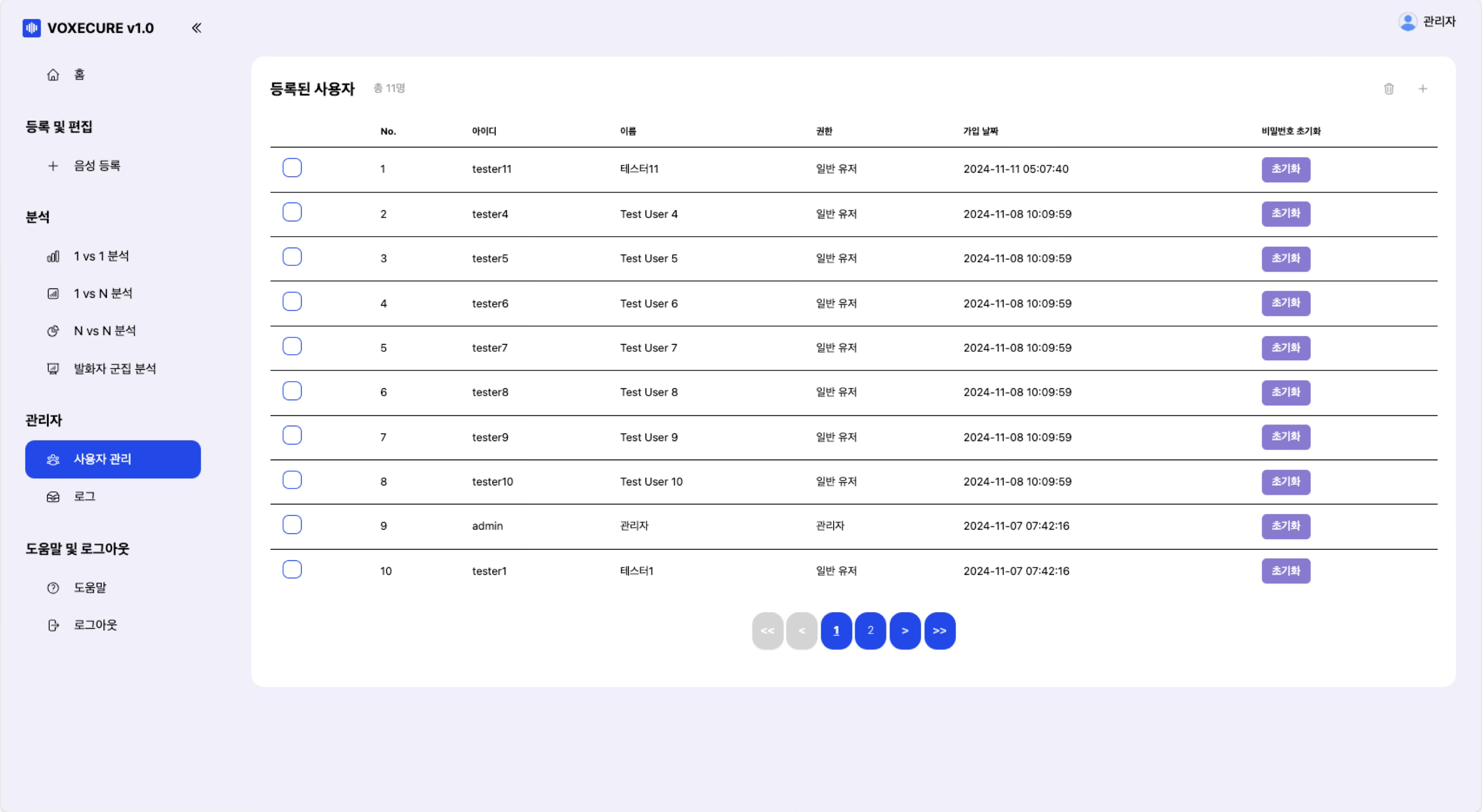
6. 관리자 기능
관리자 계정으로 로그인하면 사용자 관리(계정 생성, 비밀번호 초기화, 권한 설정)와 감사 로그(Audit Log) 확인이 가능합니다. 모든 생성(CREATE), 수정(UPDATE), 삭제(DELETE) 작업이 JSON 형태로 기록되어 완전한 추적성(Traceability)을 보장합니다. 로그인 시도 5회 실패 시 1시간 잠금 등 보안 정책이 적용되어 있습니다.

기술 스택 상세
| 영역 | 기술 |
|---|---|
| Frontend | SvelteKit 2.0, Svelte 4.2, TypeScript, Tailwind CSS 3.4, DaisyUI 4.12 |
| Frontend 시각화 | Chart.js 4.4 (우도 그래프, 바 차트, 도넛 차트), Wavesurfer.js 7.8 (파형 에디터) |
| Frontend ORM / Auth | TypeORM 0.3 (MariaDB), Lucia 3.2 (세션 기반 인증) |
| Frontend 데이터 | Axios (HTTP), ExcelJS (엑셀 내보내기), JSZip, Zod (스키마 검증), Luxon (날짜) |
| AI Server | FastAPI 0.111, Python 3.12, Uvicorn + Uvloop (비동기 고성능 서버) |
| AI / ML | PyTorch 2.4 (CUDA), TorchAudio 2.4, SpeechBrain 0.5.16, PyAnnote.audio 3.1 |
| 음성 처리 | Librosa 0.9 (오디오 특징 추출), Soundfile 0.12, FFmpeg (포맷 변환) |
| ML 알고리즘 | scikit-learn (Agglomerative Clustering), SciPy, NumPy 1.26 |
| 시각화 | Matplotlib 3.9 (t-SNE 산점도, 확률 분포 그래프 서버사이드 렌더링) |
| 데이터베이스 | MariaDB (SQLAlchemy 2.0 ORM, pool_size=20, 자동 백업) |
| GPU | NVIDIA CUDA 12.6 + cuDNN, GeForce RTX 4090 (24GB VRAM) |
| 배포 | Docker Compose (GPU 패스스루), Node.js 20 Alpine, Ubuntu 24.04 |
| 보안 | 세션 기반 인증 (Lucia), CORS/CSP 미들웨어, 로그인 시도 제한, Soft Delete |
데이터 처리 파이프라인
VOXECURE의 음성 분석은 다음과 같은 파이프라인으로 처리됩니다:
1단계: 음성 등록
WAV 파일 업로드 → PyAnnote VAD(음성 활동 감지) → 화자 분리(Diarization) → 발화 구간별 임베딩 추출(WavLM-ECAPA-TDNN) → 192차원 벡터(.npy) 저장 → 메타데이터 DB 저장
2단계: 분석 수행
분석 대상 음성 선택 → 임베딩 벡터 로딩 → 코사인 유사도 계산 → 우도비(LR) 계산(p_pos/p_neg 확률 분포 참조) → 결과 DB 저장 + JSON 응답
3단계: 결과 시각화
Chart.js 우도 그래프 렌더링 → 유사도 TOP 5 바 차트 → 교차 비교 매트릭스 → Excel 내보내기(ExcelJS)
Docker 배포 구성
전체 시스템은 Docker Compose로 통합 관리됩니다. GPU 서버에는 NVIDIA Container Toolkit을 통해 GPU를 직접 패스스루하여 딥러닝 추론 성능을 극대화합니다.
| 컨테이너 | 베이스 이미지 | 포트 | 특이사항 |
|---|---|---|---|
| python-server | nvidia/cuda:12.6.0-cudnn-runtime-ubuntu24.04 | 6003 | GPU 전체 패스스루, restart: always |
| web | node:20-alpine (Multi-stage build) | 6004 | 빌드 → 런타임 분리로 이미지 최적화 |
| MariaDB | mariadb:latest | 3306 | 자동 백업, Soft Delete 지원 |
인증 및 품질
VOXECURE는 GS 인증(Good Software 인증)을 획득한 소프트웨어입니다. TTA(한국정보통신기술협회)의 엄격한 시험을 통과하여 기능 적합성, 성능 효율성, 사용성, 신뢰성, 보안성, 유지보수성, 이식성 등 ISO/IEC 25023 품질 기준을 충족합니다.
이 프로젝트가 보여주는 우리의 역량
VOXECURE 개발을 통해, (주)민트기술은 AI/딥러닝 연구 성과를 실무 프로덕션 소프트웨어로 전환할 수 있는 풀스택 역량을 보유하고 있음을 보여줍니다. 특히 다음과 같은 과제를 수행할 수 있습니다:
- AI/딥러닝 모델의 프로덕션 서비스화 — 연구실 수준의 모델을 GPU 가속 서버 + 웹 UI로 실제 서비스 구현
- 음성/오디오 처리 시스템 — 화자 인식, 음성 활동 감지, 음성 분리, 오디오 파형 편집 등
- 법과학(Forensic) 분석 소프트웨어 — 우도비, 확률 분포, 정량적 분석 지표를 활용한 전문 분석 도구
- GPU 기반 고성능 딥러닝 서버 — CUDA + PyTorch 기반 실시간 추론 시스템 구축
- SvelteKit + FastAPI 풀스택 웹 애플리케이션 — 모던 프론트엔드 + Python AI 백엔드 통합
- Docker 기반 마이크로서비스 배포 — GPU 패스스루, Multi-stage 빌드, 환경 분리
- GS 인증 수준의 소프트웨어 품질 관리 — ISO/IEC 품질 기준을 충족하는 엔터프라이즈급 개발
- 대학/연구기관과의 산학 협력 — 연구 성과의 사업화, 기술 이전 및 제품화
음성 AI, 딥러닝 서비스화, 법과학 분석 도구 등 관련 과제가 있으시면 언제든 연락 주세요.